



In my previous job, we were offered a multifunction device with an OCR application. Nowadays, this service is quite common, but 8 years ago it was not so much. It was very easy to get used to this utility, although currently, with a much smaller machine and without that service, it seems that scans are less useful. How convenient it is to have documents just a few mouse clicks away, without having to get up and search through a mountain of papers, but it would be much better if you could perform a search for the CIF of that supplier, or that offer that came from Portugal, using a simple keyword search, something available in Windows Vista, 7, 8, and 10. Available only if the PDF is searchable.
It’s just a few papers, no big deal.
I thought. And it was true until LexNET arrived. Yes friends, the justice platform that has judicial operators so happy, has made common new concepts for Justice like electronic signature and PDF. As if they weren’t complex enough, let’s add a twist by asking for not just PDFs but PDF/A with OCR.
Irony aside, it is very practical to have PDF + OCR although the investment does not always justify it. This solution can be useful for these cases. But let’s start at the beginning.
What is a PDF/A with OCR?
This question, which may sound strange, is the definition in Annex IV of RD 1065/2015, of November 27, about electronic communications in the Administration of Justice, which regulates the LexNet system:
The main document or writing of the shipment must be presented in PDF/A format with the OCR (Optical Character Recognition) feature, that is, it must have been generated or scanned with software that allows as a final result an editable text file on which searches can be performed and must be electronically signed with the signature or signatures of the acting professionals.
Those of us who have been in this for a while will be more familiar with the term Searchable PDF (from English *Searchable PDF*).
Well, a few days ago I came across this interesting article from Aranzadi: THE COURTS BEGIN TO REJECT LAWSUITS PRESENTED WITH FORM DEFECTS IN THE USE OF LEXNET
What has happened is that many legal operators have sent digital documents in PDF, surely convinced that they were using the correct format, but now they have started to check that where they have not slipped through they have been forced to rectify, and if they haven’t done so, their documents have not been admitted.
What is the difference between a PDF and a PDF/A?
Returning to Wikipedia:
PDF/A is, in fact, a subset of PDF obtained by excluding those features superfluous for long-term archiving.
It makes sense knowing the speed of Justice ;).
What is OCR?
To define OCR we will go to the same source:
Optical Character Recognition (OCR), generally known as character recognition and frequently expressed with the acronym *OCR* (from English *Optical Character Recognition*), is a process aimed at the digitization of texts, which automatically identifies symbols or characters belonging to a certain alphabet from an image, to then store them in the form of data. Thus, we can interact with these through a text editing program or similar.
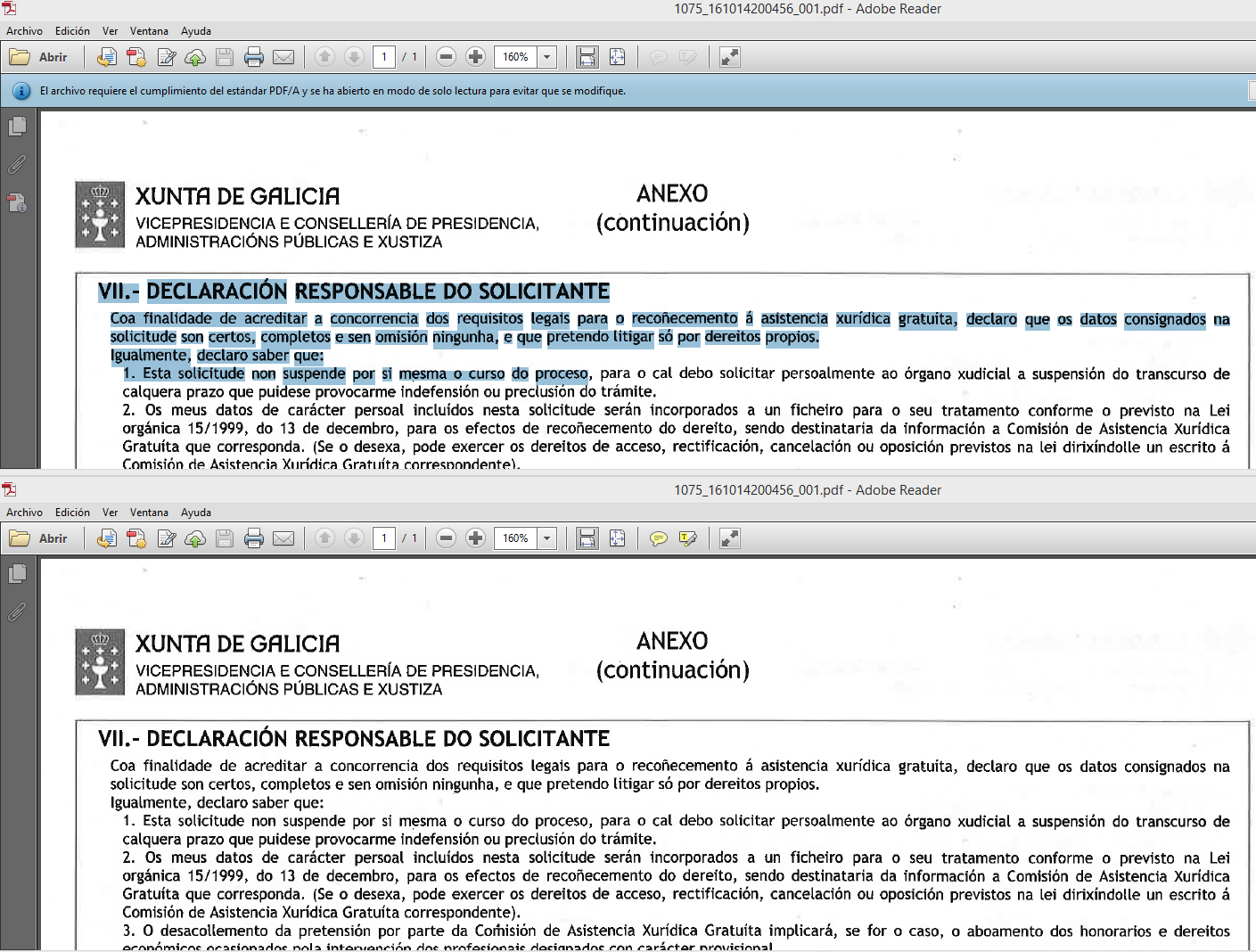
And now to make it clear, let’s see this screenshot:

The upper document is a PDF/A with OCR. As can be seen, it is possible to select the text, something impossible in the lower document, even though they appear to be identical. I suggest you do the same test with one of the PDFs you get from your digital machine or multifunction device. If you manage it, I don’t know what you’re doing reading this :).
Are you one of the others? Now comes the good part.
OCRmyPDF to the Rescue
OCRmyPDF adds an OCR text layer to PDF files, making them searchable.
That’s what OCRmyPDF, the lifesaver package, does, using:
- Tesseract OCR
- GhostScript
- Python 3
- Img2PDF
It will solve our problem.
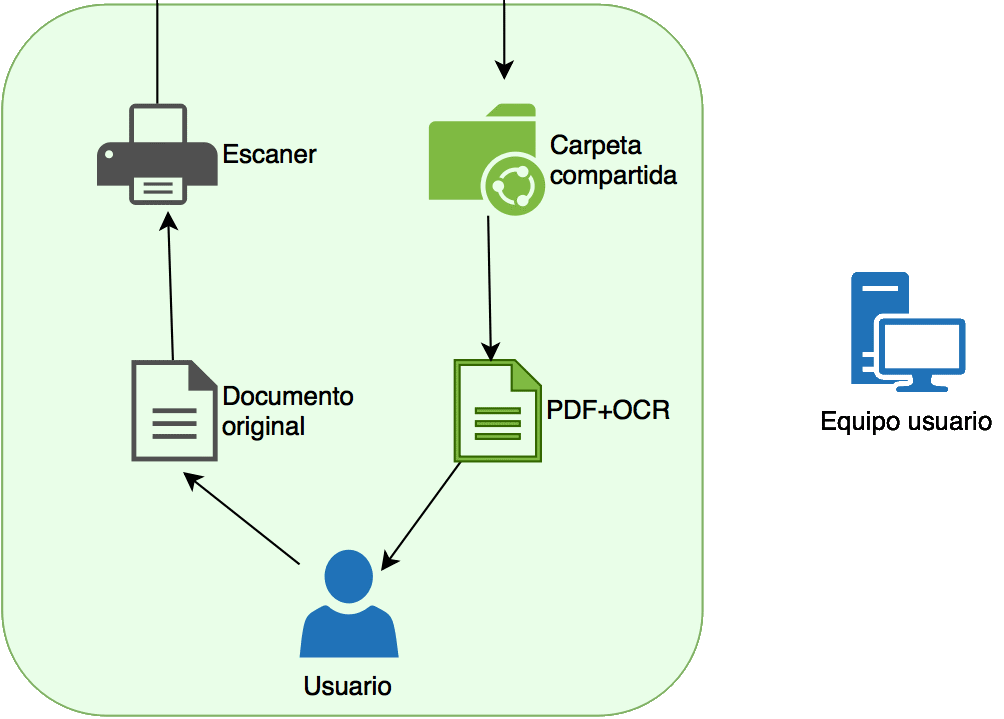
I’ve spent some time creating a couple of diagrams to illustrate what the installation consists of. The first one visualizes the service from the end-user’s perspective: I digitize a paper and get a searchable PDF/A (Yes, like the ones LexNET likes).
Obviously, the most important part is missing – the functioning. In this other diagram, the ‘guts’ of the system are shown more broadly:
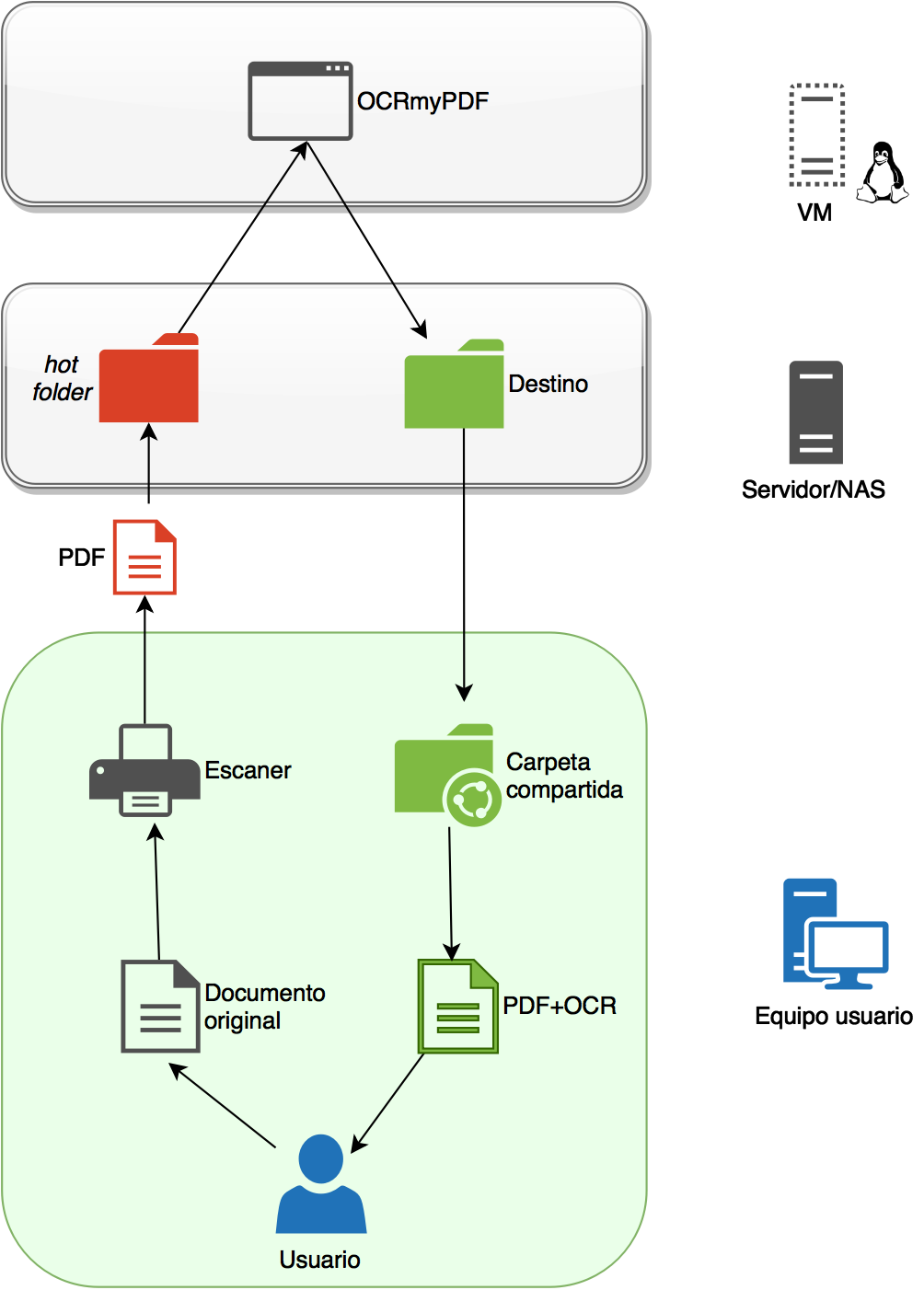
Basically, the operation would be:
- The user has an original document in paper form.
- They introduce it into the scanner, and this converts the document into a PDF.
- (Here comes the interesting part). This PDF will be saved in a hotfolder (let’s call the shared folder in which if a PDF enters it will be processed), which in my case is on an SMB server with nas4free, but it could be any NAS, a Windows server, or even, though less recommendable, the user’s own computer.
- A script with a command using OCRmyPDF will be executed on that folder, process the content, and convert it into a searchable PDF/A that will be deposited in a new shared folder, located in the same place as the hotfolder (or elsewhere).
Don’t understand? No matter, precisely some clients hire me so they don’t have to worry about these things 😉
Installation of OCRmyPDF and mount.cifs
I’ve talked a lot in the introduction, but this part will be quicker, as you need to have a basic foundation for this installation:
- We need a Debian Stretch machine (the one I’ve used) or an Ubuntu 16.10 (or higher). There’s support for Mac, for Windows through Docker, and for other Linux distributions, although I haven’t tested them. I know it’s a testing, but if you don’t want to get into apt-pinning and make your life complicated, use it. After all, it’s just setting up a service, which is not critical and we don’t have to give access to anyone, outside of the administrators.
- Once set up, run the command:
apt-get install ocrmypdf. Arm yourself with patience. Up to 345 MB will have to be downloaded, which for not having a graphical environment: Chégalle ben, as we say in my land.
- Tesseract uses training packages for each language. By default, it installs with the English one, to add more we can see this list https://packages.debian.org/search?keywords=tesseract-ocr. With this line, we would install the packages for Galician, Spanish, Basque, Catalan, and Portuguese:
apt-get install tesseract-ocr-glg tesseract-ocr-spa tesseract-ocr-cat tesseract-ocr-eus tesseract-ocr-por - At this point, we will also install a tool so that our Debian Stretch can see the Windows folders (if your equipment is Linux, you can use NFS and forget about this). For this, we are going to install the cifs-utils package with:
apt-get install cifs-utils
Now everything is installed, what’s next?
Access to the target shared folder (hotfolder) is done with the mount.cifs command:
mount.cifs //path/smb /mnt/smb -o user=username -o pass=password -o domain=domain
Here we mount in the folder /mnt/smb the network path of the destination folder of the PDFs from the scanner //path/smb.
Next, the command we must execute to perform the OCR would be:
ocrmypdf --language glg --rotate-pages -deskew --clean-final /mnt/smb/ocrin/document.pdf /mnt/smb/ocrout/document.pdf
What do the ocrmypdf options do?
- –language: Selects the language used. glg for Galician, spa for Spanish, etc…
- –rotate-pages: If you scan a page upside down, it turns it. Disproportionately increases the size of the PDF.
- –deskew: Straightens the original pdf, avoiding the typical auto-feeder documents, turned a few degrees. Very useful if it weren’t for the fact that it massively increases the size of the PDF.
- –clean: Cleans the image before performing OCR
- –clean-final: Same as the previous one, but instead of saving the original PDF, it saves the clean one. A pity that it disproportionately increases the weight of the PDF.
My recommendation, based on a short experience and the current versions of the software, is to leave it at:
ocrmypdf --language glg --clean /mnt/smb/ocrin/document.pdf /mnt/smb/ocrout/document.pdf
Finally, as we want to forget about the VM, we will need to set up a cron, so that this command is executed only every minute, and that’s it 🙂
Something important, from my point of view, is that you can take a batch of existing PDFs, copy them to the hot folder, and make them searchable. Think about contracts, or digitized invoices that are in a forgotten folder. You will be giving them new life, by being able to search within them.
I’ve had it in production for about a week with great critical and public success. If you need help getting started, you know where I am.






Leave a Reply