



En mi anterior trabajo, nos ofrecieron una multifunción con una aplicación de OCR. Hoy en día es bastante habitual este servicio, pero hace 8 años no lo era tanto. Fue muy fácil acostumbrarse a esa utilidad, aunque en la actualidad, con una máquina mucho más pequeña y sin ese servicio, parece que las digitalizaciones son menos útiles. Qué cómodo es tener los documentos a unos clicks de ratón de distancia, sin levantarse para no tener que buscar entre la montaña de papeles, pero sería mucho mejor si se pudiera realizar una búsqueda por el CIF de aquel proveedor, o aquella oferta que te llegó desde Portugal, utilizando una simple búsqueda por palabras clave, algo disponible en las versiones de Windows Vista, 7, 8 y 10. Disponible sólo si el PDF es buscable.
Son pocos papeles, no importa.
Pensé. Y era cierto hasta que llegó LexNET. Sí amigos, la plataforma de justicia que tiene tan contentos a los operadores judiciales, ha hecho habituales para conceptos nuevos para la Justicia como firma electrónica y PDF. Por si no fueran suficientemente complejos, rizaremos el rizo pidiendo no sólo PDFs sino PDF/A con OCR.
Ironías a parte, es de lo más práctico disponer de PDF + OCR aunque la inversión no lo justifica siempre. Esta solución puede ser de utilidad para estos casos. Pero comencemos por el principio.
¿Qué es un PDF/A con la característica OCR?
Esta pregunta que puede sonar rara, es la definición existente en el punto 5 del anexo IV del RD 1065/2015, de 27 de noviembre, sobre comunicaciones electrónicas en la Administración de Justicia, por el que se regula el sistema LexNet:
El escrito o documento principal del envío deberá ser presentado en el formato PDF/A con la característica OCR (reconocimiento óptico de caracteres), es decir, deberá haber sido generado o escaneado con software que permita obtener como resultado final un archivo en un formato de texto editable sobre cuyo contenido puedan realizarse búsquedas y deberá ir firmado electrónicamente con la firma o firmas de los profesionales actuantes.
Los que ya llevamos un tiempo en esto, estaremos más familiarizados con el término PDF buscable (del inglés Searchable PDF).
Bien, hace unos días llegaba a este interesante artículo de Aranzadi: LOS TRIBUNALES COMIENZAN A INADMITIR DEMANDAS PRESENTADAS CON DEFECTOS DE FORMA EN EL EMPLEO DE LEXNET
Lo que ha pasado es que muchos operadores jurídicos han enviado documentos digitalizados en PDF, seguramente convencidos de que utilizaban el formato correcto, pero ahora han empezado a comprobar que donde no hayan colado les han obligado a subsanar, y si no lo han hecho, no les habrán admitido los documentos.
¿Qué diferencia hay entre un PDF y un PDF/A?
Volviendo a la wikipedia:
PDF/A es, de hecho, un subconjunto de PDF obtenido excluyendo aquellas características superfluas para el archivado a largo plazo.
Tiene sentido sabiendo de la velocidad de la Justicia ;).
¿Qué es OCR?
Para definir OCR acudiremos a la misma fuente:
El reconocimiento óptico de caracteres (ROC), generalmente conocido como reconocimiento de caracteres y expresado con frecuencia con la sigla OCR (del inglés Optical Character Recognition), es un proceso dirigido a la digitalización de textos, los cuales identifican automáticamente a partir de una imagen símbolos o caracteres que pertenecen a un determinado alfabeto, para luego almacenarlos en forma de datos. Así podremos interactuar con estos mediante un programa de edición de texto o similar.
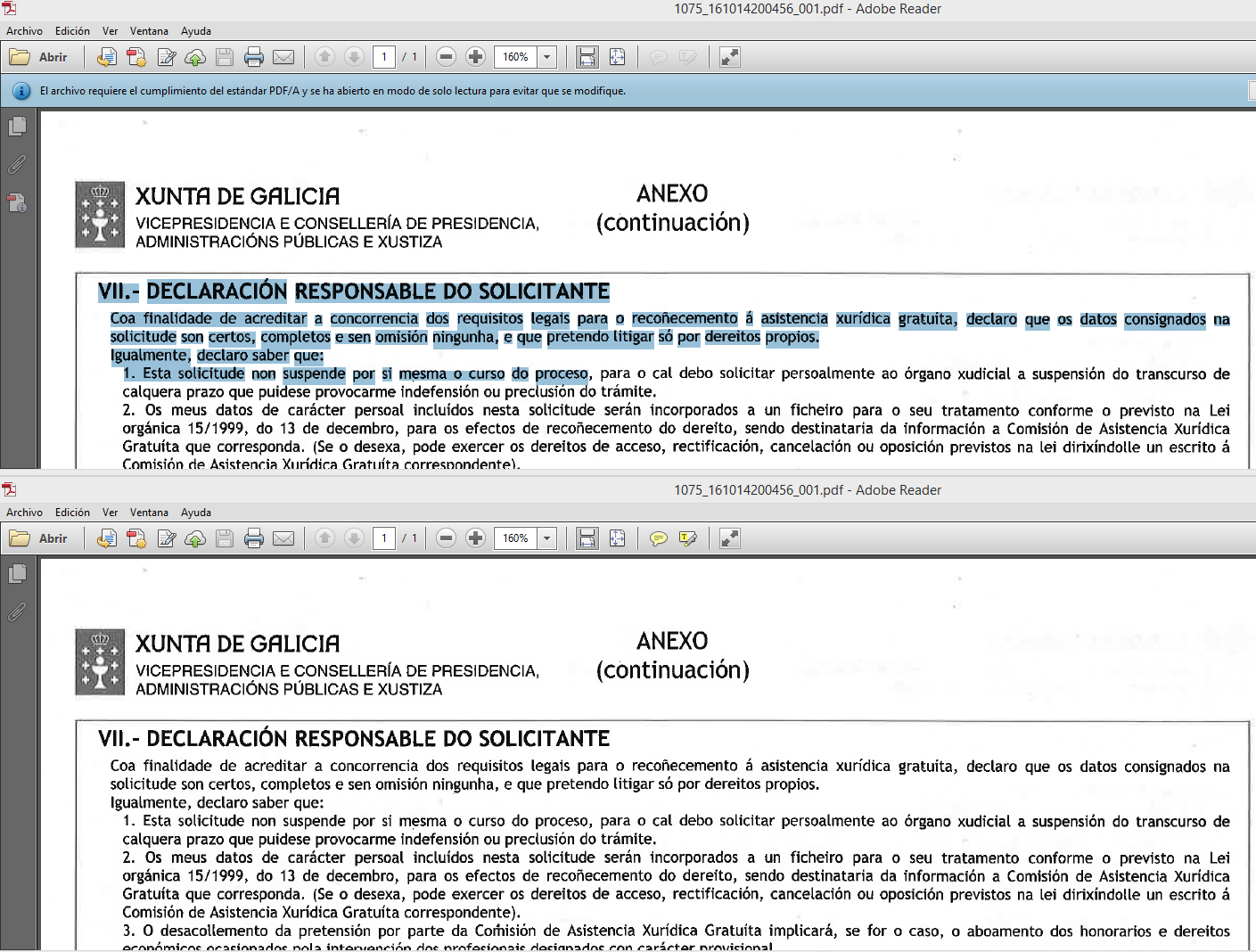
Y ahora para que quede claro, veamos esta captura de pantalla:
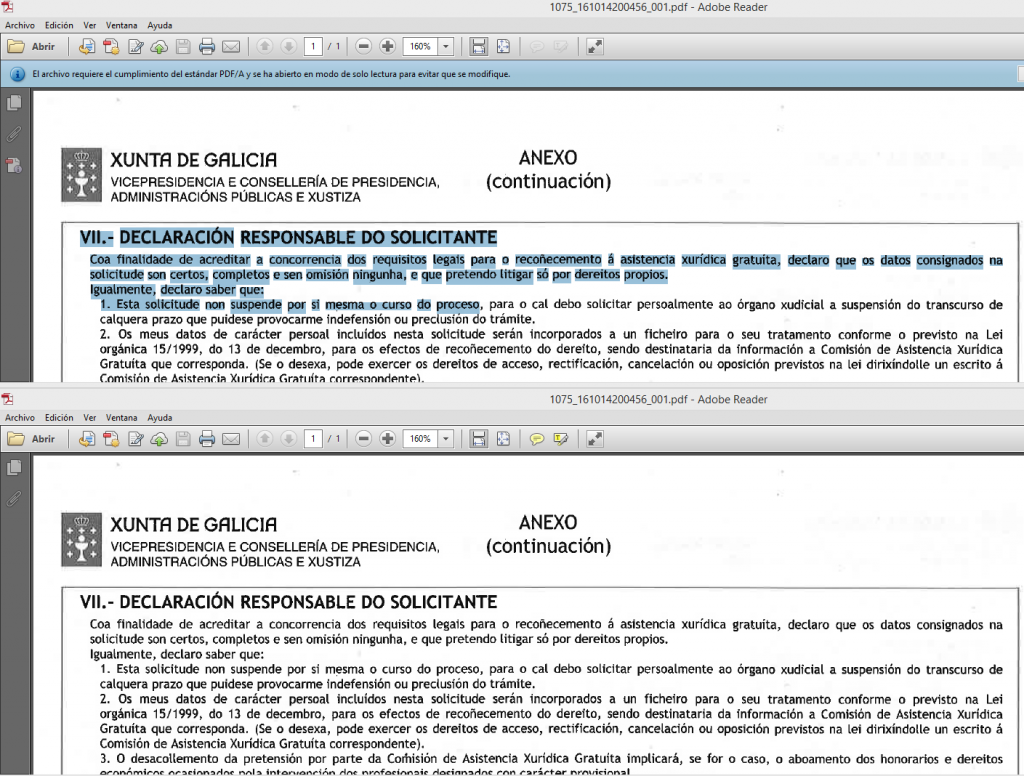
El documento superior es un PDF/A con OCR. Como se puede apreciar es posible seleccionar el texto, cosa imposible en el documento inferior, aún siendo aparentemente iguales. Te propongo, realizar esta misma prueba con uno de los PDFs que obtienes de tu máquina digitalizadora o multifunción. Si lo consigues, no se que haces leyendo esto :).
¿Eres de los otros? Ahora viene lo bueno.
OCRmyPDF al rescate
OCRmyPDF añade una capa de texto OCR a los ficheros PDF, convirtiéndolos en buscables.
En eso consiste OCRmyPDF, el paquete salvador, que utilizando:
- Tesseract OCR
- GhostScript
- Python 3
- Img2PDF
Nos va a solucionar el problema.
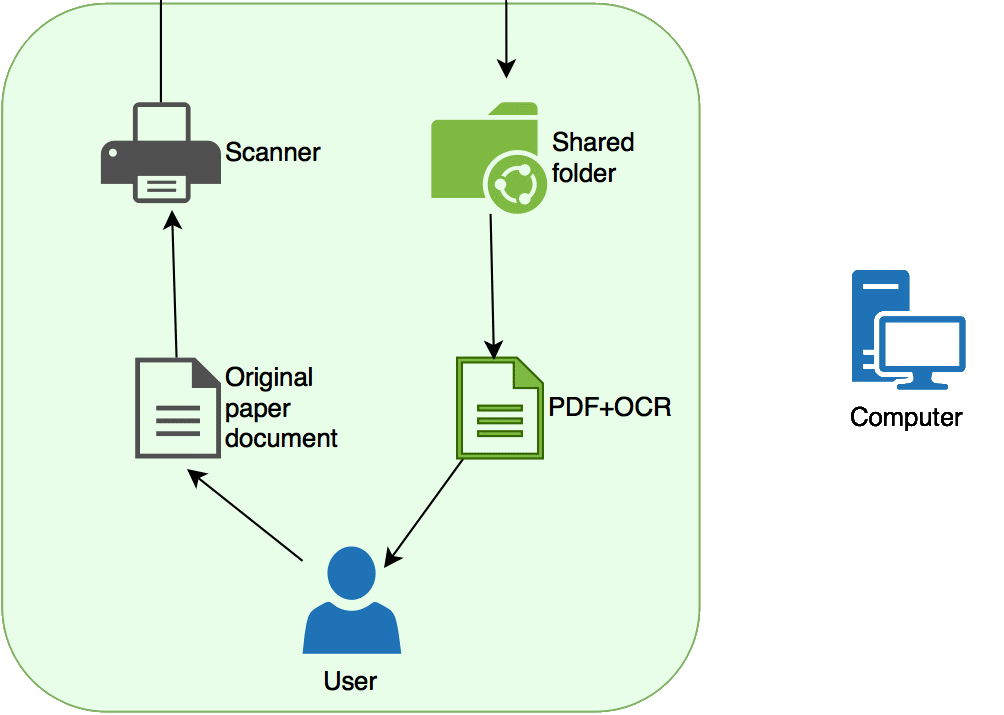
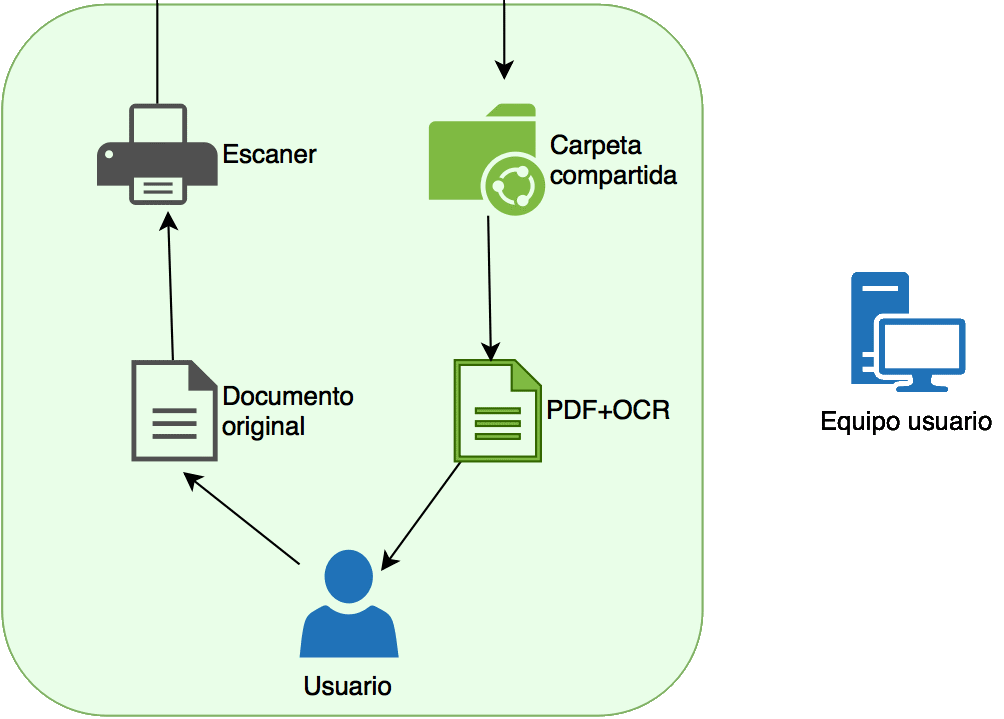
He dedicado un rato a realizar un par de esquemas para ilustrar en que consiste la instalación. El primero visualiza el servicio desde el punto de vista del usuario final: Digitalizo un papel y obtengo un PDF/A buscable (Sí, como los que les gusta a los de LexNET).
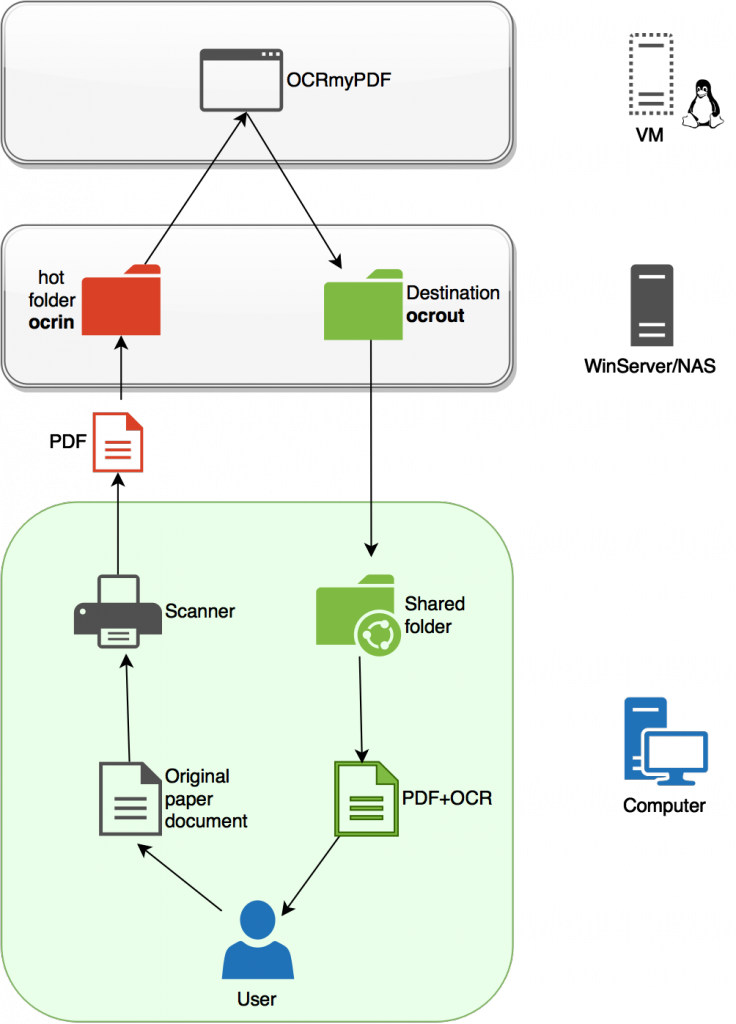
Obviamente falta la parte más importante lo que sería el funcionamiento. En este otro diagrama se muestra de manera más amplia lo que serían las tripas del sistema:
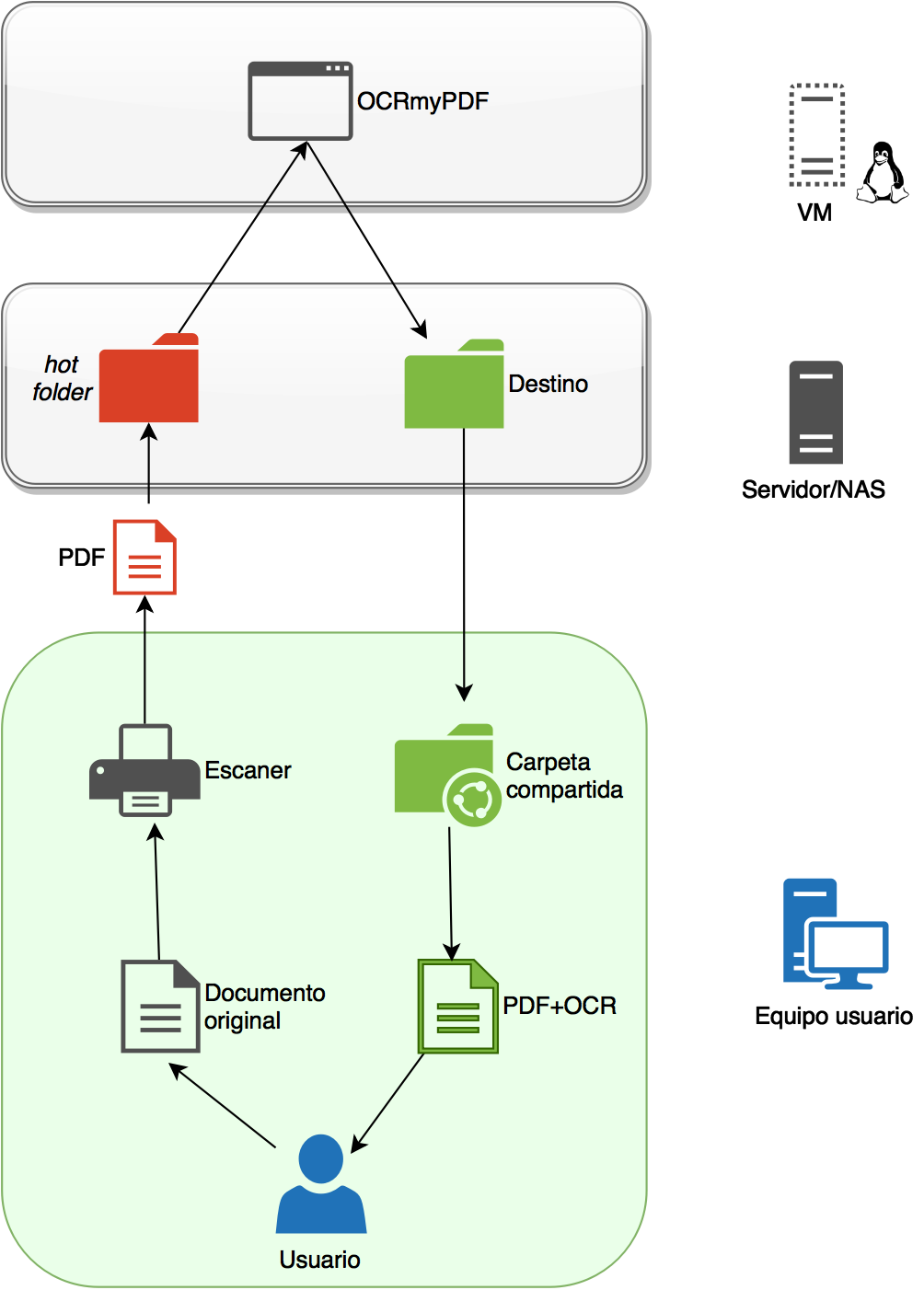
Básicamente el funcionamiento sería:
- El usuario tiene un documento original en papel.
- Lo introduce en el escáner y esto convierte el documento en un PDF.
- (A partir de aquí viene lo interesante). Este PDF se guardará en un hotfolder (llamaremos así a la carpeta compartida en la que si entra un PDF será procesado), que en mi caso está en un servidor SMB con una nas4free, pero que podría ser una NAS cualquiera, un servidor windows, o incluso aunque sería el menos recomendable de los escenarios el propio equipo del usuario.
- Un script con un comando que utiliza OCRmyPDF se ejecutará sobre esa carpeta, procesará el contenido y lo convertirá en PDF/A buscable que depositará en una nueva carpeta compartida, presente en la misma ubicación que el hotfolder (o en otra).
¿No te has enterado? Da igual, precisamente algunos clientes me contratan para no tener que enterarse de estas cosas 😉
Instalación de OCRmyPDF y mount.cifs
Me he enrollado mucho en la introdución, pero esta parte será más rápida, ya que habrá que tener una base mínima para realizar esta instalación:
- Necesitamos una máquina Debian Stretch (la que yo he usado) o una Ubuntu 16.10 (o superior). Hay soporte para Mac, para Windows a través de Docker, y para otras distribuciones Linux, aunque no los he probado. Ya se que es una testing, pero si no te quieres poner a hacer apt-pinning y complicarte la vida, la usas. Al fin y al cabo, sólo se va a montar un servicio, que no es crítico y al que no tenemos porque dar acceso a nadie, fuera de los administradores.
- Una vez montada corremos el comando:
apt-get install ocrmypdf. Ármate de paciencia. Hasta 345 MB se tendrán que descargar, que para no tener entorno gráfico: Chégalle ben, como diríamos en mi tierra.
- Tesseract utilizar unos paquetes de entrenamiento para cada idioma. Por defecto se instala con el de inglés, para añadir más podemos ver esta lista https://packages.debian.org/search?keywords=tesseract-ocr. Con esta línea instalaríamos los paquetes de gallego, castellano, euskera, catalá y portugués:
apt-get install tesseract-ocr-glg tesseract-ocr-spa tesseract-ocr-cat tesseract-ocr-eus tesseract-ocr-por - Llegado este momento también instalaremos una herramienta para que nuestra Debian Stretch vea las carpetas windows (si tu equipo es Linux, puedes utilizar NFS y olvidarte de esto). Para ello vamos a instalar el paquete cifs-utils con:
apt-get install cifs-utils
Ya está todo instalado ¿ahora qué?
El acceso a la carpeta compartida de destino (hotfolder) lo realizamos con el comando mount.cifs:
mount.cifs //ruta/smb /mnt/smb -o user=usuario -o pass=contraseña -o domain=dominio
Aqui montamos en la carpeta /mnt/smb la ruta de red de la carpeta de destino de los PDF desde el escaner //ruta/smb.
A continuación el comando que debemos ejecutar para que realice el OCR sería:
ocrmypdf --language glg --rotate-pages -deskew --clean-final /mnt/smb/ocrin/documento.pdf /mnt/smb/ocrout/documento.pdf
¿Qué hacen las opciones de ocrmypdf?
- –language: Selecciona el idioma utilizado. glg para gallego, spa para español, etc…
- –rotate-pages: Si digitalizas alguna hoja al revés la gira. Incrementa desproporcionadamente el tamaño del PDF.
- –deskew: Endereza el pdf original, evitando los típicos documentos de alimentador automático, girados unos grados. Muy útil si no fuera por que incrementa masivamente el tamaño del PDF.
- –clean: Limpia la imagen antes de realizar el OCR
- –clean-final: Igual que el anterior pero en lugar de guardar el PDF original, guarda el limpio. Una lástima que incremente desproporcionadamente el pesdo del PDF.
Mi recomendación basada en una corta experiencia y en las versiones actuales de software es dejarlo en:
ocrmypdf --language glg --clean /mnt/smb/ocrin/documento.pdf /mnt/smb/ocrout/documento.pdf
Finalmente, como queremos desentendernos de la VM, habrá que programa un cron, de manera que este comando se ejecute sólo cada minuto, y listo 🙂
Algo importante, desde mi puesto de vista, es que se puede coger un lote de pdfs existentes, copiarlos a la hot folder y convertirlos en buscables. Piensa en contratos, o facturas digitalizadas que se encuentren en una carpeta olvidada. Les estarás dando nueva vida, al poder buscar en ellos.
Lo tengo en producción desde hace una semanita con gran éxito de crítica y público. Si necesitas ayuda en la puesta en marcha, ya sabes donde estoy,





Deja una respuesta